2.3 Strumenti Semantici come Soluzione Strategica
Per contribuire a mitigare questo rischio economico e ridurre i costi improduttivi, l’ENEA ha avviato, tra le varie iniziative, lo sviluppo sperimentale di un sistema di analisi semantica e linguistica basato sui testi (abstract) della memoria storica dell’Ente (FP7, Horizon 2020, Horizon Europe, Euratom).
La tesi alla base di questo strumento si fonda sul riscontro che il registro linguistico impiegato negli abstract delle proposte di successo risulta strettamente allineato alla terminologia del bando di riferimento. Una rapida verifica di questa coerenza testuale, nelle fasi iniziali di redazione, può fornire indicazioni preziose per ottimizzare la proposta progettuale, uniformandola al linguaggio e ai criteri che i valutatori si aspettano di riscontrare.
L’obiettivo ultimo è quindi fornire ai ricercatori uno strumento agile per verificare la validità e l’allineamento di una proposta, prima di investire centinaia di ore di lavoro nella sua scrittura.
Funzionalità dell'Ambiente Semantico
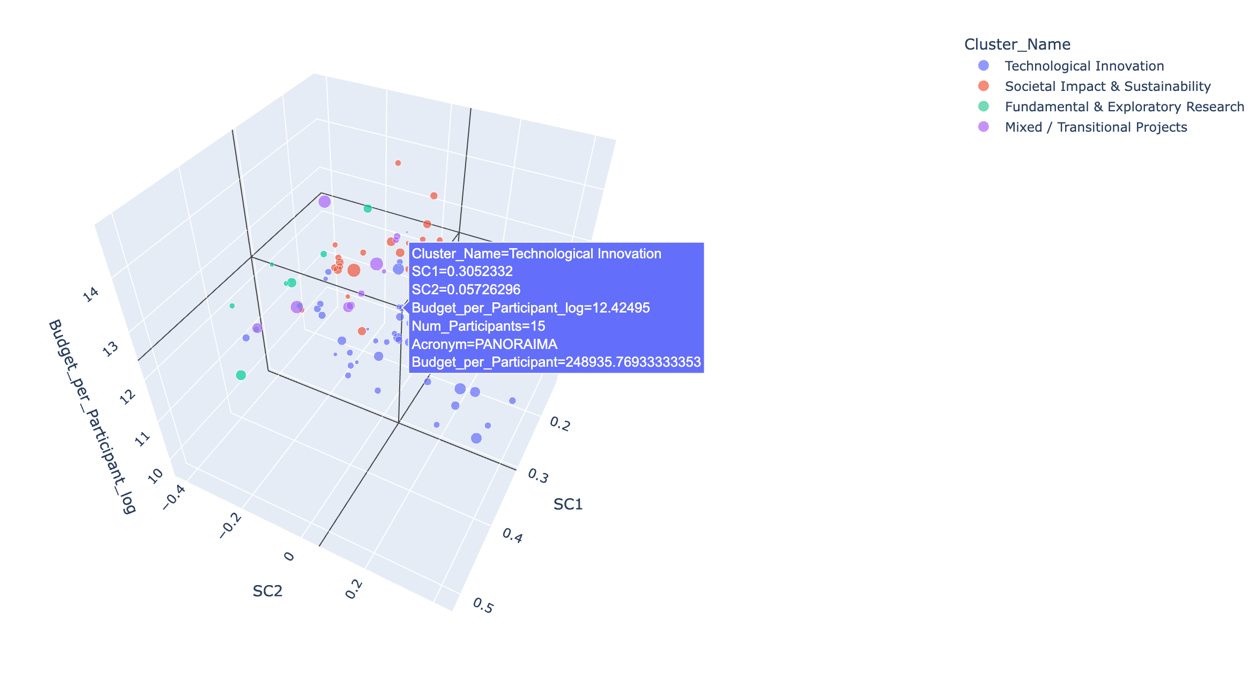
- Analisi dei Landscape 3D: Mappatura dei progetti in cluster tematico-narrativi (es. Societal Impact, Technological Innovation, Fundamental Research).
- Interrogazione Semantica Rapida: Inserendo parole chiave (es. "green"), il sistema estrae istantaneamente i progetti storici simili e il loro grado di correlazione (es. KijaniBox, similarity 0.222), permettendo di riutilizzare competenze e strutture già premiate dalla Commissione Europea.
- Correlazione Retorica-Economica: Il sistema incrocia la chiarezza narrativa con le variabili economiche (budget complessivo e dimensioni del consorzio), dimostrando graficamente che i progetti con strutture narrative più strutturate e orientate all'impatto sono statisticamente associati a budget più elevati e migliori tassi di successo.
Il sistema è stato sviluppato come ambiente sperimentale interno, destinato a supportare le attività di analisi e proposal management.
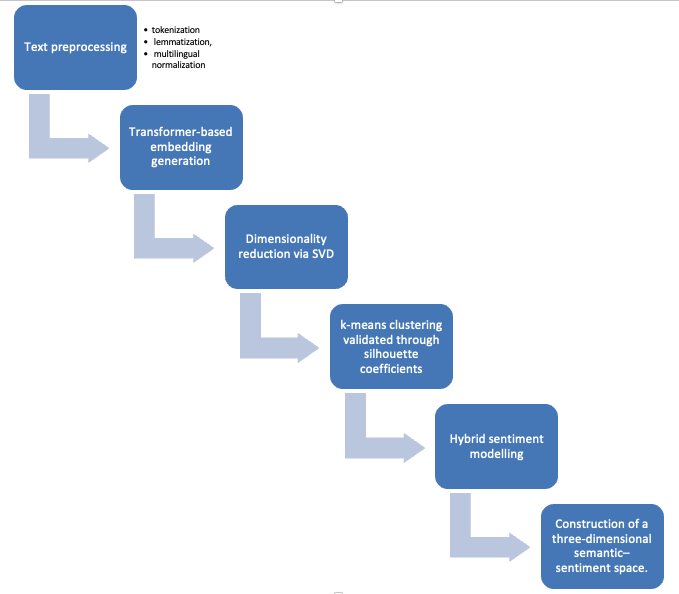
Il processo inizia con una fase di preprocessing testuale (vedi Figura 3), comprendente tokenizzazione, lemmatizzazione e normalizzazione multilingue dei testi. Successivamente, vengono generati embedding semantici mediante modelli transformer, in grado di rappresentare il contenuto testuale in forma vettoriale ad alta dimensionalità.
Nella fase seguente, la dimensionalità degli embedding viene ridotta tramite Singular Value Decomposition (SVD), al fine di preservare le componenti informative più rilevanti e semplificare l’analisi. I vettori ridotti vengono poi sottoposti a clustering mediante algoritmo k-means, con validazione della qualità dei cluster attraverso i coefficienti di silhouette.
Infine, il framework integra un modello ibrido di sentiment analysis che combina informazione semantica ed emotiva, permettendo la costruzione di uno spazio tridimensionale semantico-sentimentale, utile per rappresentare e interpretare le relazioni tra contenuti, polarità emotive e distribuzione dei cluster.
L’analisi costi-benefici può essere rappresentata graficamente mettendo in relazione le componenti semantiche con il budget. L’asse z rappresenta il budget ponderato rispetto al numero di partecipanti, mentre il diametro delle sfere rappresenta il budget complessivo del progetto.